-
Infrastruktur allgemein prüfen
-
Freigaben für IP Adressen prüfen
-
gibt es mehrere ausgehende IP Adressen, welche ggf. in der Firewall der Zieldatenbank freigeschalten werden müssen ?
-
ändert sich die IP Adresse der Zieldatenbank ? Besonders bei Azure Datenbanken ist das oft der Fall, da diese über Load Balancer etc. geroutet werden ?
-
prüfen Sie diese Dinge ausführlich anhand dieser Anleitung Wie gebe ich IP Adressen frei und prüfe IP Adressbereiche
-
-
Windows Eventlog anschauen
-
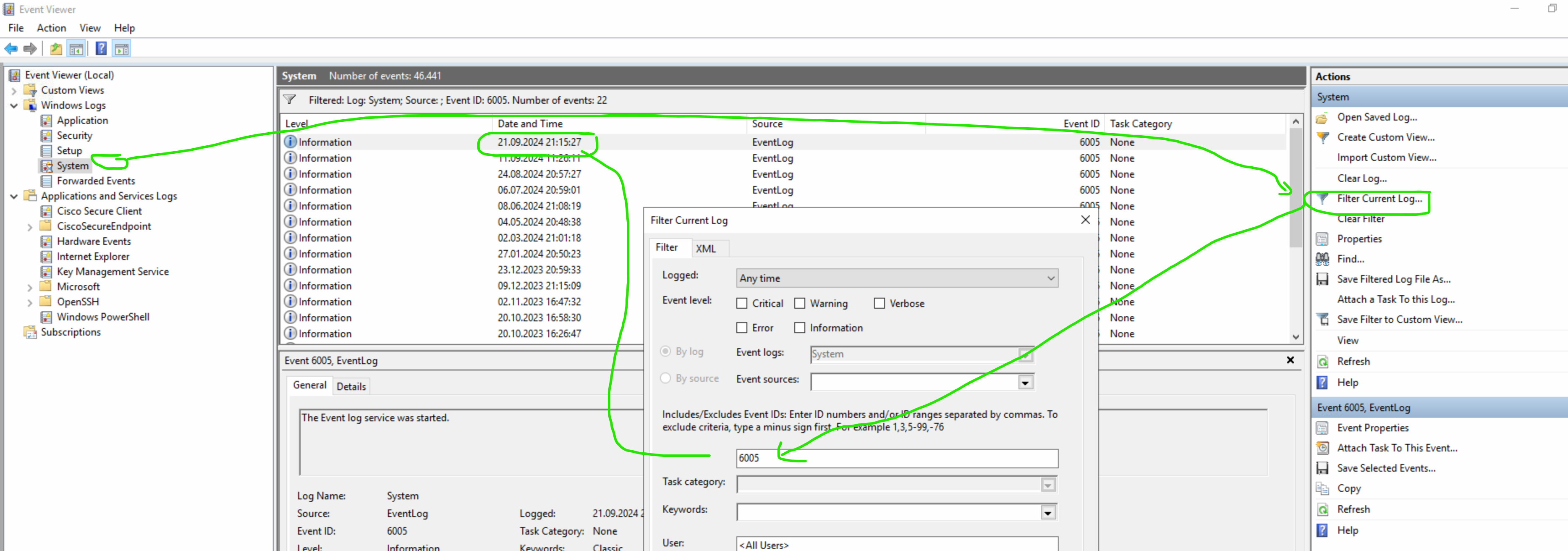
Wurde der Computer neu gestartet ? Systemevents filtern auf 6005 (Neustart des Eventlogs)
-
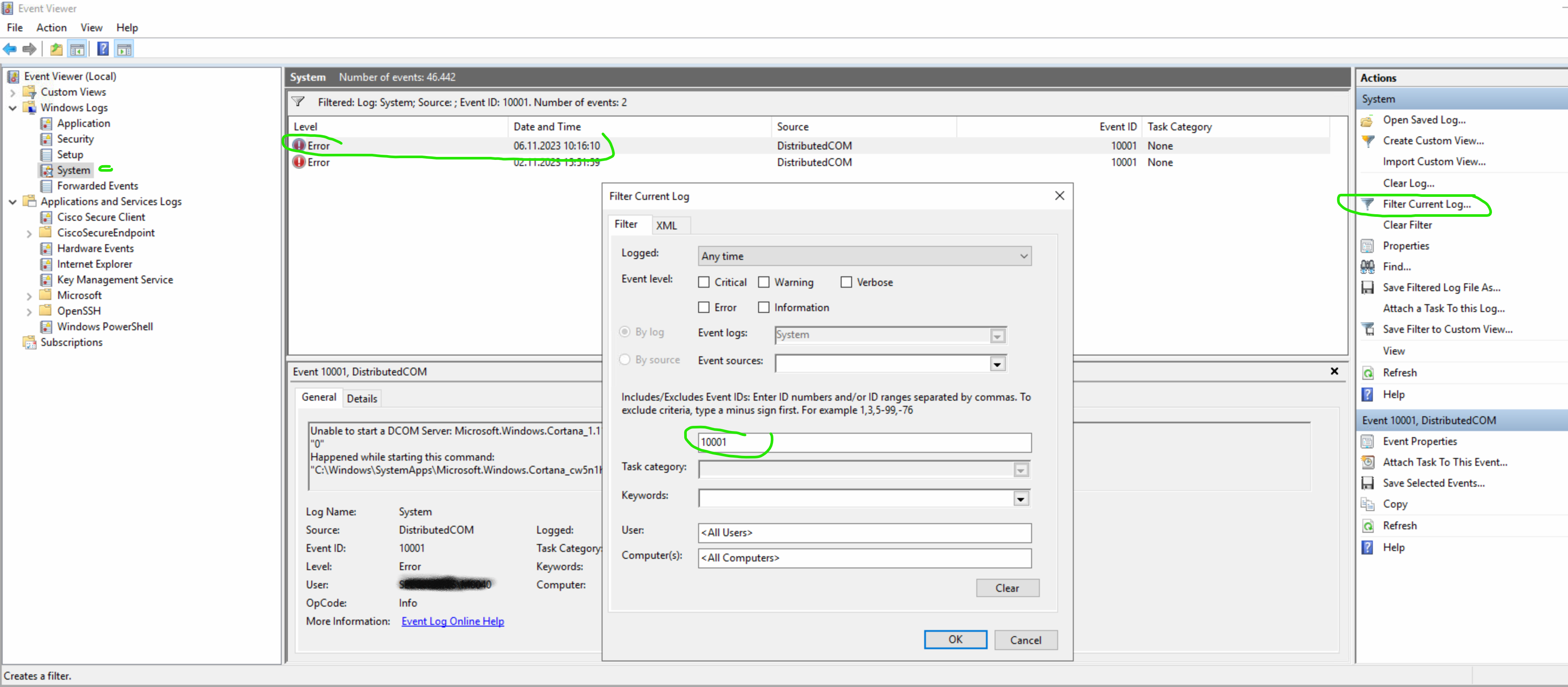
Wurde die Netzwerkverbindung getrennt ? Systemevents filtern auf 10001
-
-
-
SQL Server Performance verbessern
-
das Kompatibilitätslevel der Datenbank so hoch wie möglich setzen, die Ausführungspläne werden dann effizienter
-
alle Tabellen einmal über die Funktion ALTER TABLE …. REBUILD neu bauen lassen (Insbesondere HEAP Tabellen mit vielen DELETE / INSERTS werden so wieder klein) (s.Script 1)
-
Prüfung, ob die Datenbank im Wiederherstellungsmodell Simple ist
-
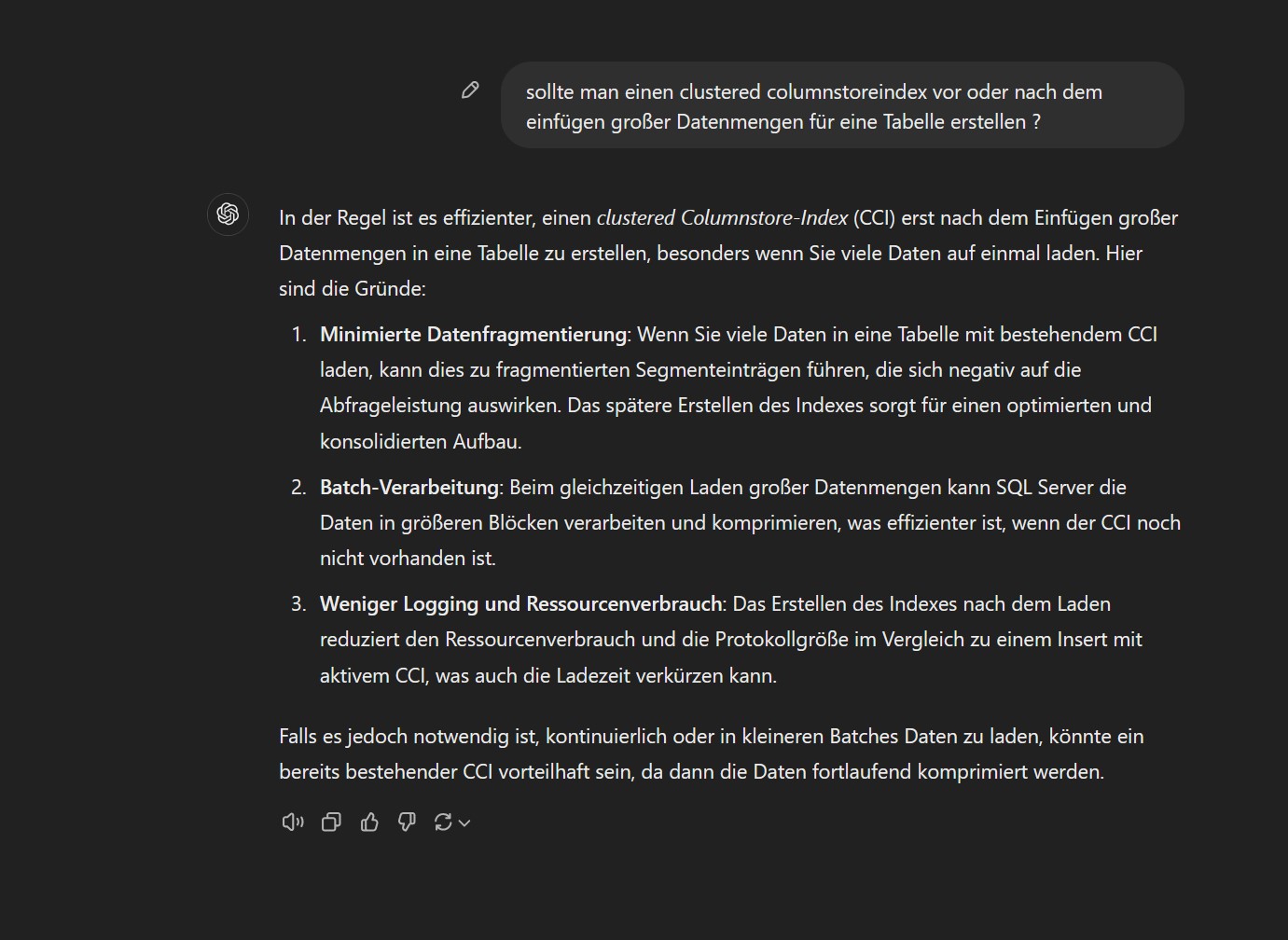
die Neuerstellung von Columnstore Indexen nach dem Einfügen der Daten vornehmen (nicht vorher) oder auf eine letzten Step separieren, um zu sehen ob, der Rest läuft
-
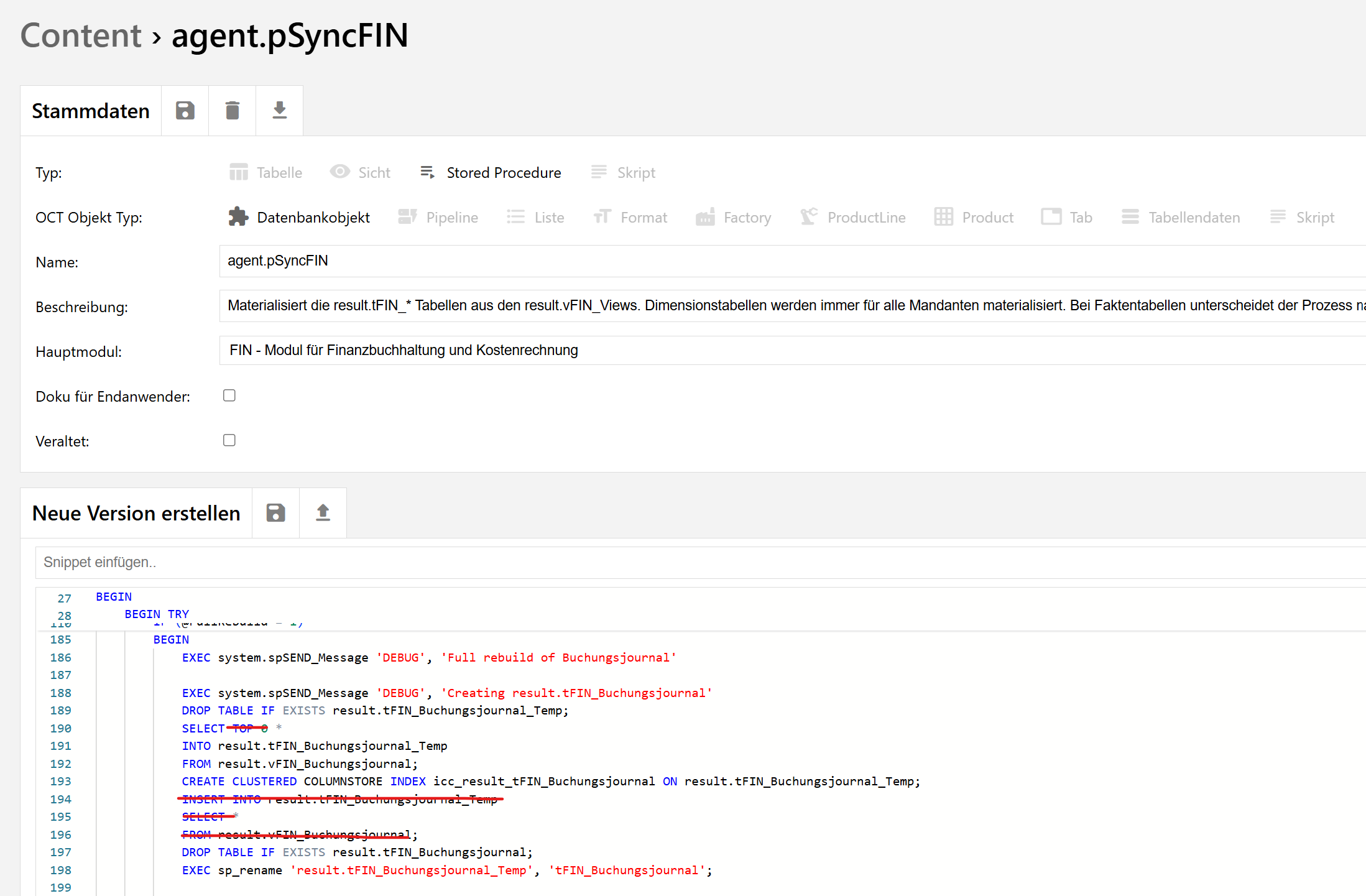
derzeit sollte das testweise in der Prozedur agent.spSyncFIN erfolgen, falls diese im Einsatz ist
-
Größe der tempdb prüfen und vergrößeren bzw. prüfen ob ob Wachstum möglich ist
-
-
OCT Logs prüfen
-
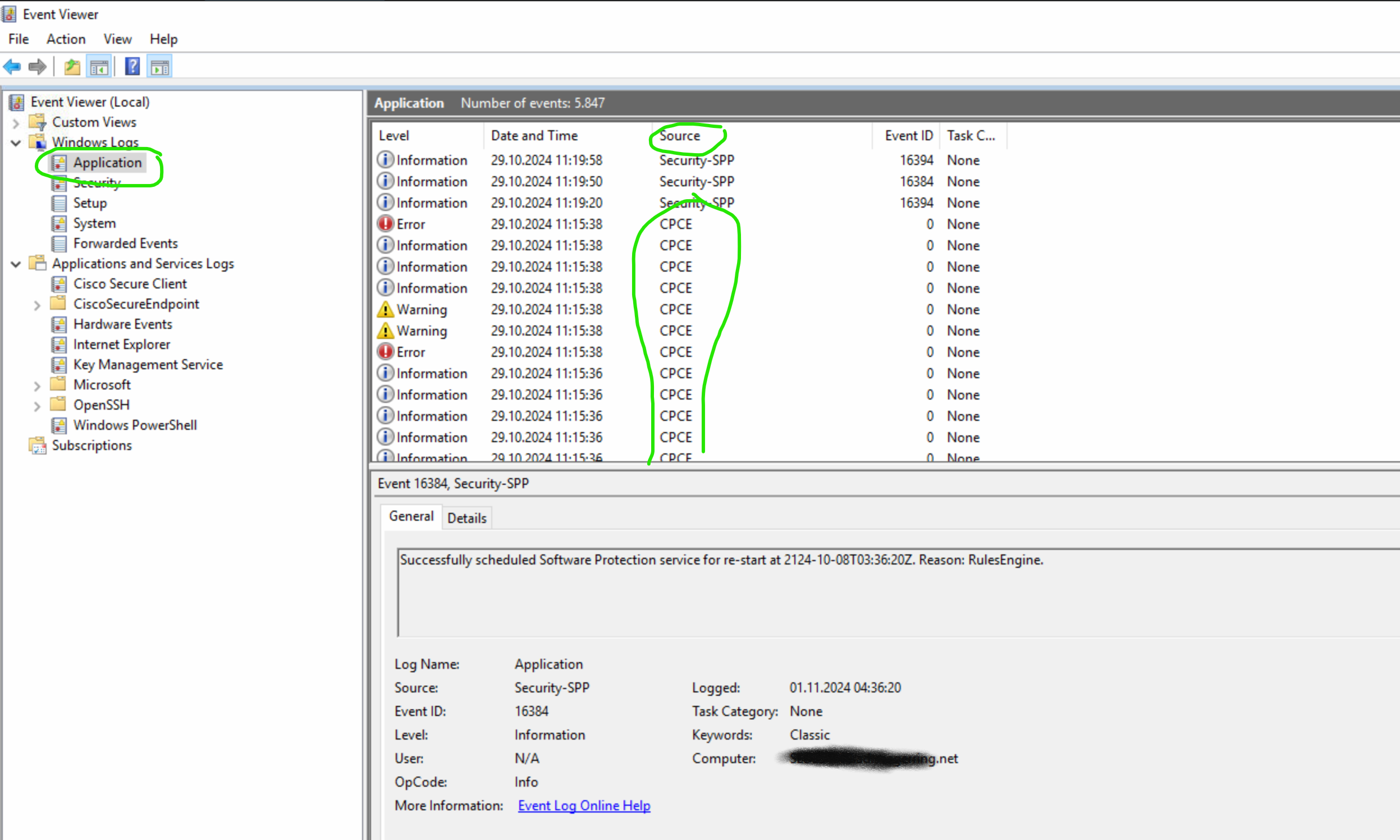
Windows Applikationslog prüfen, gefiltert auf Source CPCE / OCT
-
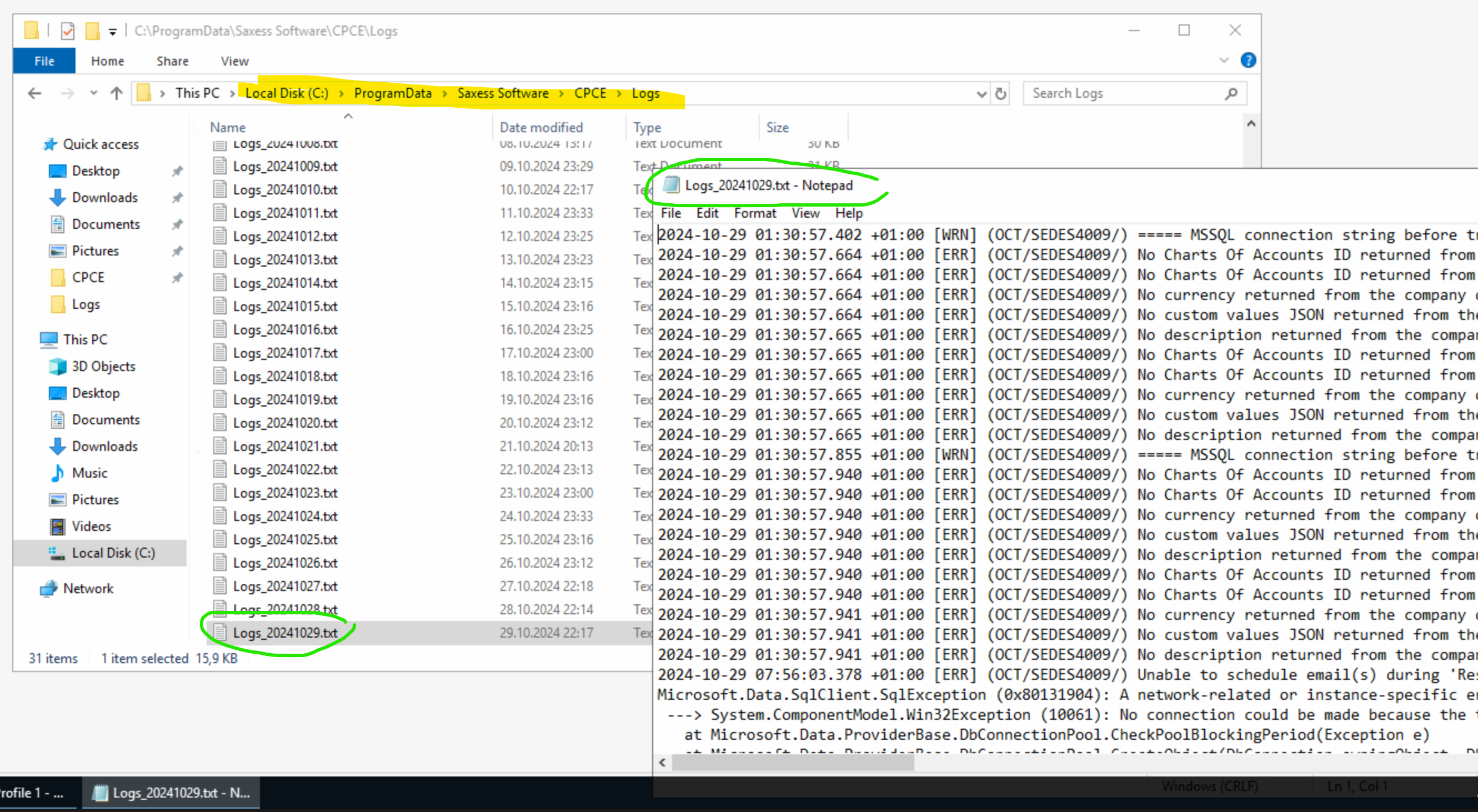
OCT Logfiles prüfen C:\ProgramData\Saxess Software\CPCE\Logs
-
OCT API Log prüfen
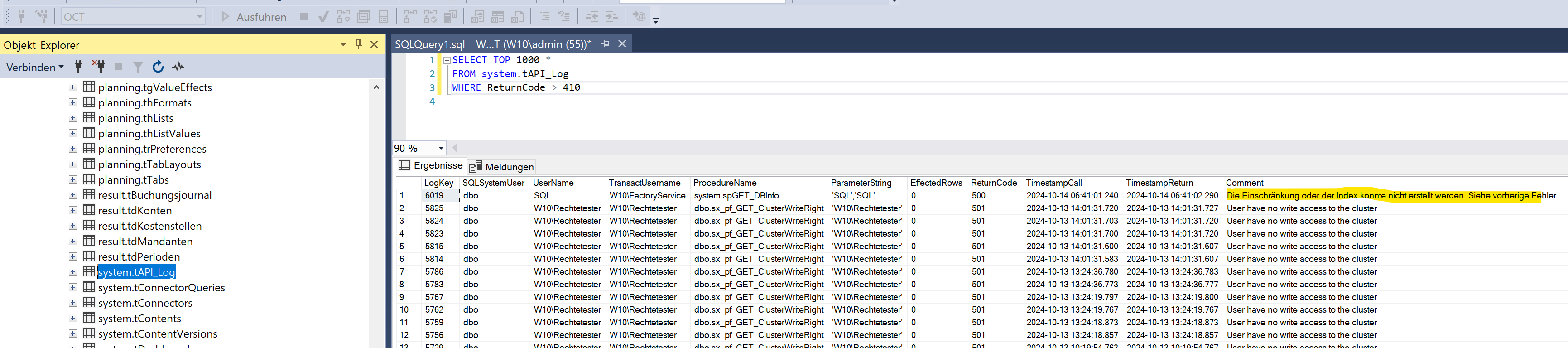 SQL
SQLSELECT TOP 1000 * FROM system.tAPI_Log WHERE ReturnCode > 410
-
-
OCT Konfiguration
-
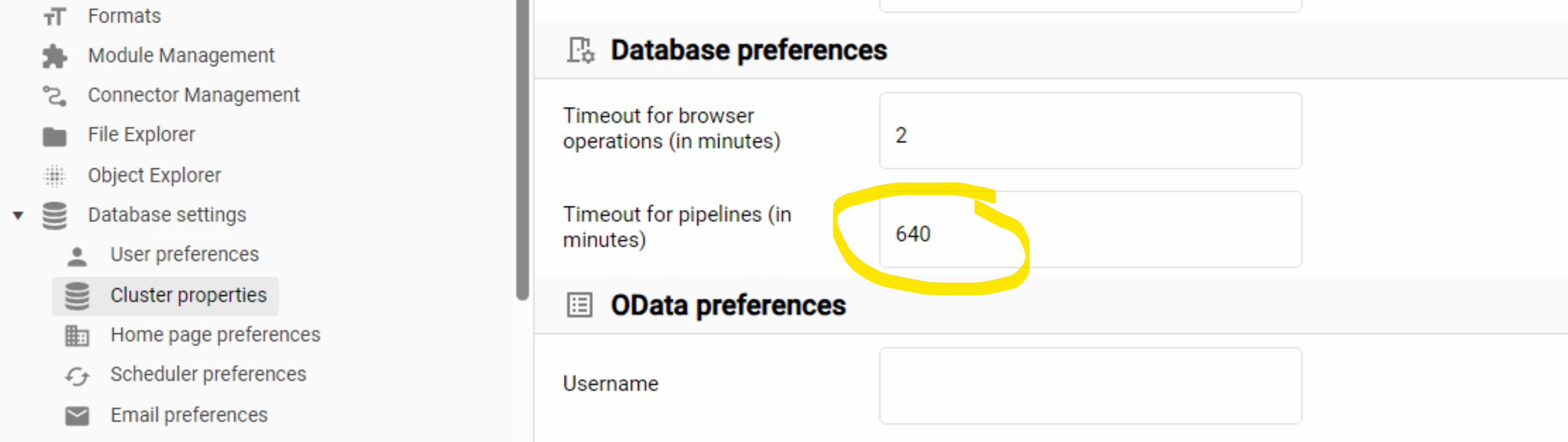
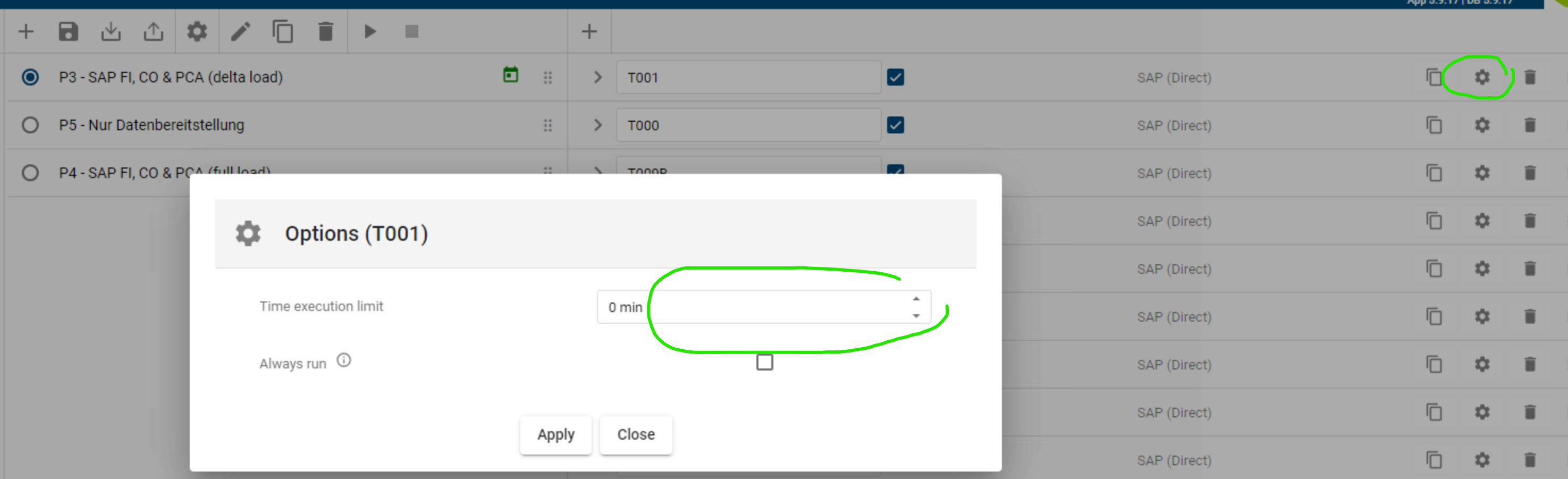
Timeout für Pipelines Setting prüfen
-
ist am Step ein Zeitlimit hinterlegt, welches ggf. zu knapp bemessen ist ?
-
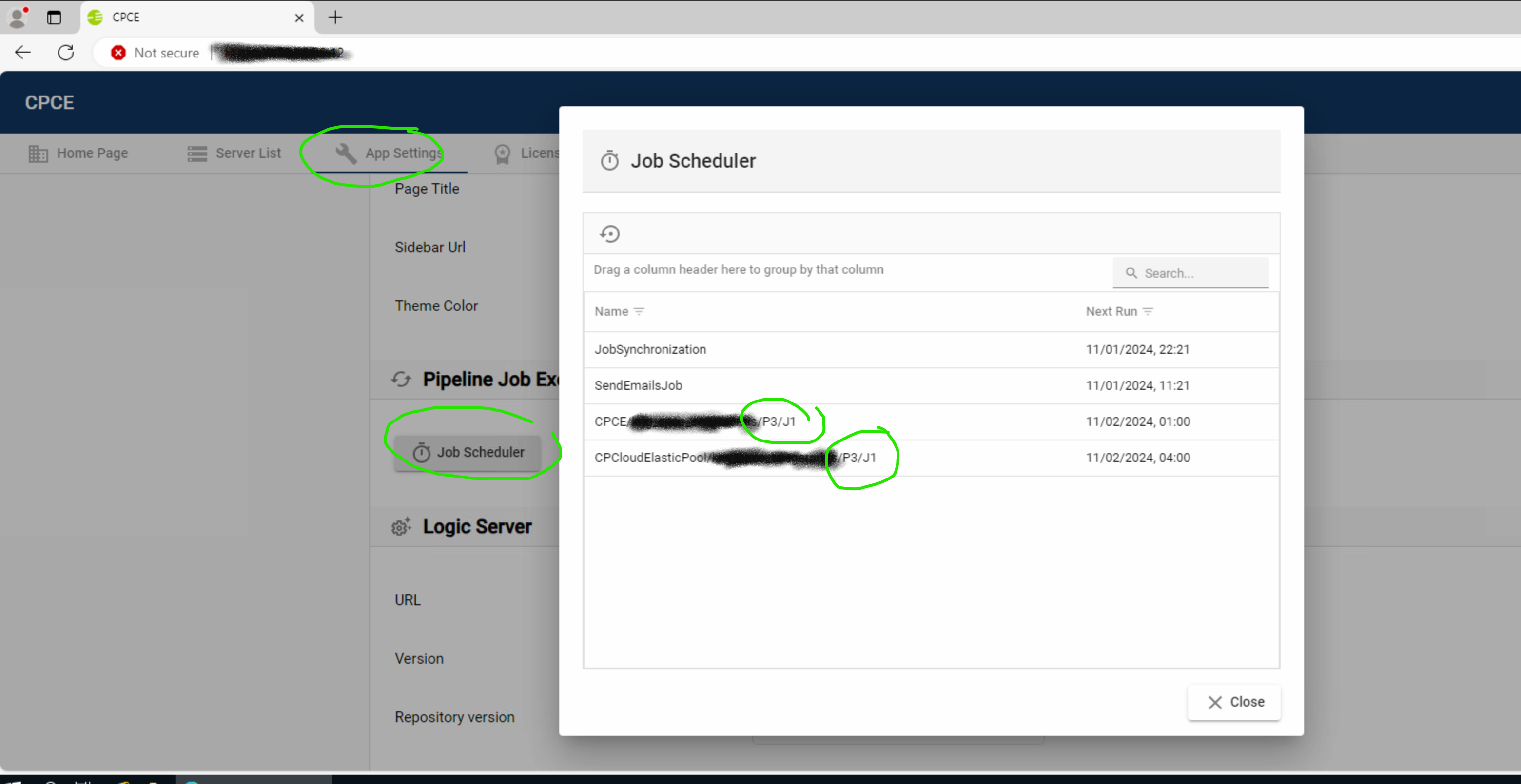
steht der Job korrekt im Ausführungsplan des Servers ?
-
-
ETL Strategie verbessern
-
die Pipeline in Transportpipeline und Aufbereitungspipeline trennen
-
die Transportpipeline transportiert nur die Daten von Quelle zum Ziel
-
die Aufbereitungspipeline bereit im Zielserver auf
-
die Aufbereitung kann so separat noch mal angestoßen werden, oft sogar auf dem Zielserver separat von der sendenden OCT Instanz
-
-
-
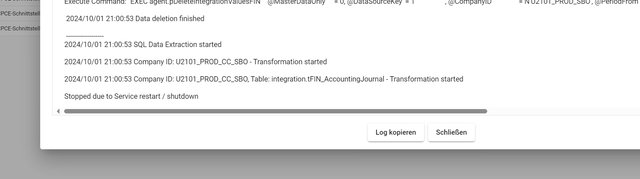
Im Log gibt es die Meldung “Stopped due to service restart / shutdown”
-
Es könnte ein Problem mit dem Watchdog Prozess geben - dieser startet den Service neu, falls er gestoppt wurde. Falls der Service auf die Anfrage des Watchdog nicht reagiert (da er schwer beschäftigt ist), kann dieser den Service stoppen und neustarten. Die Pipeline bricht dadurch ab. Unter
ProgramData/Saxess Software/<service instance>/service.appsettings.jsonkann das Watchdog Intervall von 60 auf 0 geändert werden, der Watchdog prüft dann nicht den Service. .jira-issue { padding: 0 0 0 2px; line-height: 20px; } .jira-issue img { padding-right: 5px; } .jira-issue .aui-lozenge { line-height: 18px; vertical-align: top; } .jira-issue .icon { background-position: left center; background-repeat: no-repeat; display: inline-block; font-size: 0; max-height: 16px; text-align: left; text-indent: -9999em; vertical-align: text-bottom; } SXSEOCT-2933 -
die Meldung kann natürlich auch kommen, falls der Computer neu gestartet wurde - gab es aber keinen Computerneustart, war es wahrscheinlich der Watchdog
-